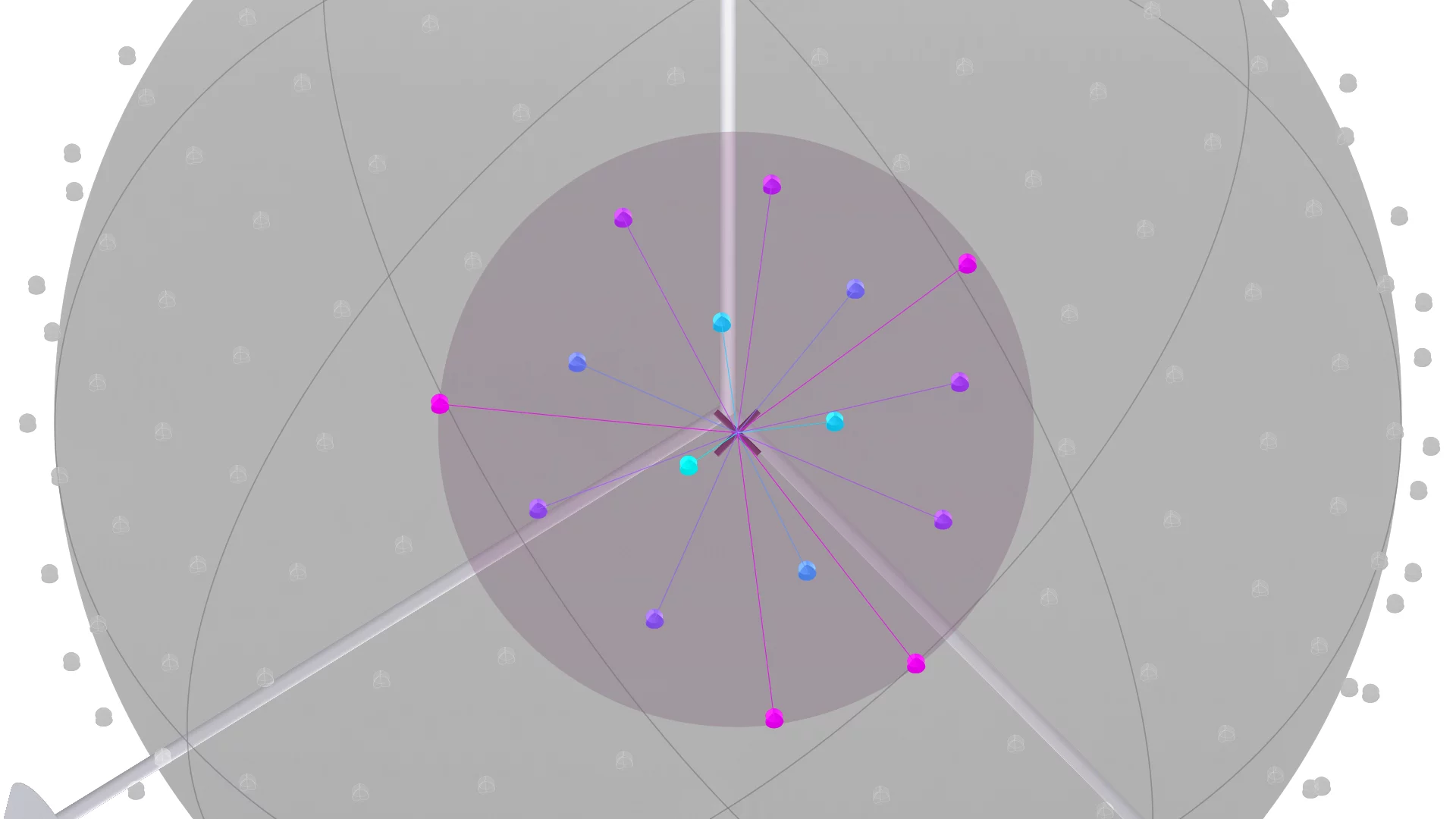
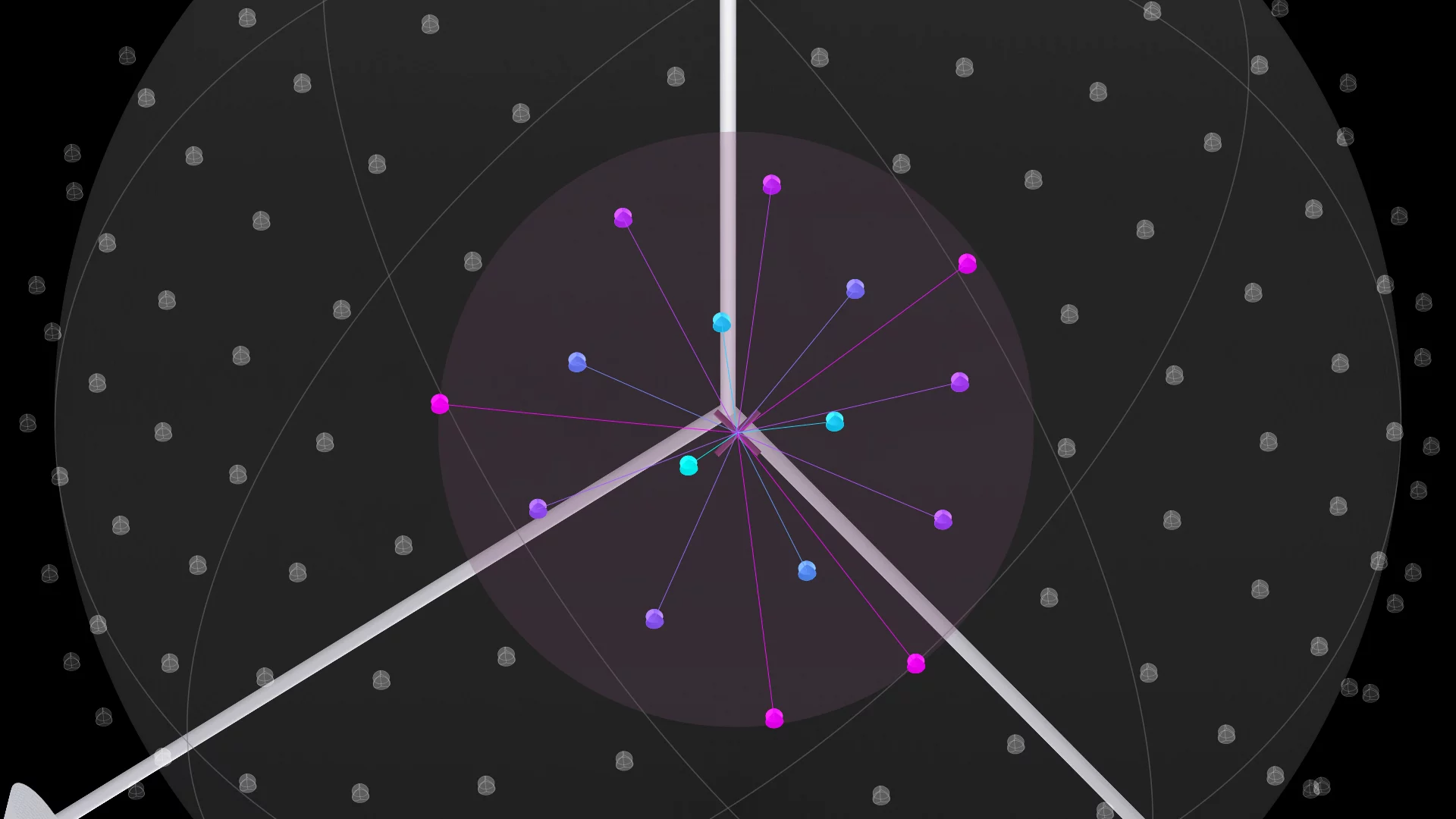




Abstract
We present Unified Spherical Frontend (USF), a distortion-free lens-agnostic framework that transforms images from any calibrated camera onto the unit sphere via ray-direction correspondences, and performs spherical resampling, convolution, and pooling canonically in the spatial domain. USF is modular: projection, location sampling, value interpolation, and resolution control are fully decoupled. Its configurable distance-only convolution kernels offer rotation-equivariance while avoiding harmonic transforms entirely. USF scales efficiently to high-resolution spherical imagery and maintains less than 1% performance drop under random test-time rotations without training-time rotational augmentation, and enables zero-shot generalization to any unseen (wide-FoV) lenses with minimal performance degradation.
Motivation
Most vision pipelines apply planar CNNs that assume a pinhole camera and operate on regular 2D grids. Each camera type (pinhole, fisheye, panoramic) has a unique projection geometry, forcing practitioners to train separate, lens-specific models that inevitably overfit onto the distortion patterns they see. This is mathematically unavoidable: by Gauss’s Theorema Egregium, no flat projection preserves the intrinsic curvature of the sphere, so any 2D representation inevitably distorts geometry.
A model is rotation-equivariant if rotating its input produces an equivalently rotated output. This is a desirable property for any system where camera orientation may vary at test time. USF achieves both lens-agnostic processing and rotation-equivariance while supporting plug-and-play replacement of planar layers in any existing backbone, providing a generic framework for modern vision.
Methodology
Click the diagram to explore
Unified Spherical Frontend. (i) A planar image and its lens normal map can be combined to form a (ii) spherical image. Cameras with different lenses produce spatially varying densities and distributions of pixels when projected onto the sphere. Thus, it is crucial to perform (iii) resampling before (iv) feeding into the backbone composed of spherical convolution and pooling layers. Optionally, the results can be (v) resampled back into the raw projected spherical image pixel locations, and (vi) unprojected back to the planar image for downstream integration.
Results
We replace standard planar layers with spherical counterparts while keeping all other aspects of the models and training protocol identical. All evaluation is performed in the planar domain for consistency. NR and RR denote non-rotated and randomly rotated settings. Prior spectral-domain spherical CNNs are compared only in the low-resolution MNIST experiment due to their prohibitive cost at higher resolutions.
Rotation Equivariance
| Model | NR ↑ | RR ↑ |
|---|---|---|
| Planar | 98.45% | 41.08% |
| S²CNN | 96% | 94% |
| SO(3) CNN | 98.7% | 98.1% |
| (1) Spherical Dis PWC ×3 | 87.18% | 85.43% |
| (2) Spherical Dis MLP [8,8], L=0 | 67.01% | 65.74% |
| (3) Spherical Dis MLP [8,8], L=6 | 92.13% | 91.50% |
| (4) Spherical Dis×Dir MLP [16,16], L=8 | 98.28% | 43.54% |
Spherical MNIST Classification. All models trained without random rotation. L denotes Fourier embedding levels. Variants (1)–(3) are distance-only (rotation-equivariant); (4) includes direction (gauge-dependent).
| Model | Train | Test NR | Test RR | ||
|---|---|---|---|---|---|
| mAP₁₀↑ | mAP₅₀↑ | mAP₁₀↑ | mAP₅₀↑ | ||
| R-CenterNet | NR | 35.73% | 22.7% | N/A | N/A |
| Planar YOLOv11 | NR | 39.65% | 24.41% | 12.71% | 4.66% |
| RR | 27.76% | 9.99% | 28.01% | 10.24% | |
| Spherical YOLOv11 | NR | 29.54% | 11.41% | 29.59% | 7.90% |
Object Detection on PANDORA. 360° panoramas with oriented bounding boxes (RBFoV). All spherical convolutions use 3-segment discrete PWC distance weighting.
| Model | Train | Test NR | Test RR | ||
|---|---|---|---|---|---|
| mIoU ↑ | mAcc ↑ | mIoU ↑ | mAcc ↑ | ||
| Planar DeepLab v3 | NR | 35.01% | 58.30% | 12.11% | 22.50% |
| RR | 32.29% | 52.89% | 38.30% | 53.99% | |
| Planar UNet | NR | 33.33% | 55.48% | 12.91% | 23.40% |
| RR | 33.75% | 51.13% | 35.91% | 51.52% | |
| Planar YOLOv11 | NR | 28.32% | 48.09% | 8.17% | 16.43% |
| RR | 28.53% | 44.39% | 30.62% | 45.13% | |
| Spherical DeepLab v3 | NR | 28.78% | 45.27% | 28.09% | 41.18% |
| RR | 30.55% | 44.58% | 32.59% | 45.38% | |
| Spherical UNet | NR | 25.72% | 42.20% | 22.99% | 35.29% |
| RR | 25.07% | 40.85% | 27.83% | 41.81% | |
| Spherical YOLOv11 | NR | 24.29% | 40.59% | 15.61% | 28.08% |
| RR | 21.52% | 38.88% | 24.05% | 38.98% | |
Semantic Segmentation on Stanford 2D-3D-S. Three backbones (DeepLab v3, UNet, YOLOv11) with identical distance-only 3-segment PWC kernels. RGB-only input, 3-fold cross-validation.
Across all tasks, distance-only spherical kernels maintain strong performance under arbitrary rotations without augmentation, while planar models degrade sharply. The distance × direction kernel captures orientation-sensitive cues but sacrifices equivariance. Expressivity depends heavily on kernel parameterization: a low-level MLP underperforms a simple piecewise-constant design, highlighting the importance of appropriate embeddings.
Zero-Shot Lens Generalization
We evaluate cross-lens adaptability by training on one lens type and testing on all three. Pinhole (90° FoV, 280×280), fisheye (180° FoV, 560×560), and panoramic lenses are simulated from equirectangular images with matched pixel-to-FoV ratios.
| Model | Train | Test Pinhole | Test Fisheye | Test Panoramic | |||
|---|---|---|---|---|---|---|---|
| mIoU ↑ | mAcc ↑ | mIoU ↑ | mAcc ↑ | mIoU ↑ | mAcc ↑ | ||
| Planar DeepLab v3 | Pinhole | 42.53% | 55.75% | 33.53% | 47.36% | 36.07% | 53.61% |
| Fisheye | 39.88% | 53.46% | 40.05% | 55.86% | 33.11% | 56.53% | |
| Panoramic | 29.66% | 43.85% | 24.91% | 37.54% | 35.01% | 58.30% | |
| Spherical DeepLab v3 | Pinhole | 34.76% | 47.47% | 22.36% | 35.52% | 19.70% | 35.09% |
| Fisheye | 19.44% | 31.52% | 30.44% | 44.21% | 28.16% | 43.99% | |
| Panoramic | 12.57% | 23.05% | 28.35% | 41.58% | 28.78% | 45.27% | |
Zero-Shot Lens Generalization (Full-Dataset). Trained on one lens, tested on all three. Random rotation disabled. Spherical models show more consistent cross-lens transfer, especially between lenses with similar FoV coverage.
Planar models show clear performance drops when evaluated on a different lens from training. Spherical models transfer more consistently across lenses, especially when source and target share similar FoV coverage. Degradation is more noticeable between views with drastically different FoV (e.g., pinhole to panoramic) due to mismatched spatial coverage.
Computation Benchmark
All benchmarks use a 960×480 panorama input with batch size 8, RGB channels, averaged over 10 runs on an NVIDIA H200 GPU (PyTorch 2.8.0, CUDA 12.8, float32).
Cold-start cost is dominated by geometric preprocessing (neighborhood construction, interpolation weights). Once cached, runtime drops to the millisecond level across all sampling methods.
Three spherical convolution variants compared against planar Conv2d (5×5 kernel, matching the ~25–30 neighbor receptive field). Discrete PWC sparse achieves the fastest sustained runtime; the continuous MLP variant benefits most from weight caching at inference.
Planar and spherical versions of YOLOv11, DeepLab v3, and UNet with identical macro-architectures. Spherical networks often require fewer FLOPs but take longer in wall-clock time, since planar operators use heavily optimized CUDA kernels.
Geometry caching is the key enabler: once neighborhood structures and interpolation weights are precomputed, sustained runtime drops by orders of magnitude. Without caching, geometric preprocessing would dominate and make spherical pipelines infeasible at scale. With caching, spherical networks train at roughly 2× the wall-clock time of planar counterparts, which we consider acceptable given the added geometric consistency, rotation equivariance, and lens-agnostic processing.
Citation
@inproceedings{yu2026usf, title = {{Unified} {Spherical} {Frontend}: {Learning} {Rotation}-{Equivariant} {Representations} of {Spherical} {Images} from {Any} {Camera}}, author = {Yu, Mukai and Dabhi, Mosam and Xie, Liuyue and Scherer, Sebastian and Jeni, László A.}, year = {2026}, month = jun, booktitle = {{IEEE}/{CVF} {Conference} on {Computer} {Vision} and {Pattern} {Recognition} ({CVPR})}, publisher = {IEEE}}@misc{yu2025usf, title = {{Unified} {Spherical} {Frontend}: {Learning} {Rotation}-{Equivariant} {Representations} of {Spherical} {Images} from {Any} {Camera}}, author = {Yu, Mukai and Dabhi, Mosam and Xie, Liuyue and Scherer, Sebastian and Jeni, László A.}, year = {2025}, month = nov, publisher = {arXiv}, doi = {10.48550/arXiv.2511.18174}, url = {https://arxiv.org/abs/2511.18174}, eprint = {2511.18174}, archiveprefix = {arXiv}, primaryclass = {cs.CV}, abstract = {Modern perception increasingly relies on fisheye, panoramic, and other wide field-of-view (FoV) cameras, yet most pipelines still apply planar CNNs designed for pinhole imagery on 2D grids, where pixel-space neighborhoods misrepresent physical adjacency and models are sensitive to global rotations. Traditional spherical CNNs partially address this mismatch but require costly spherical harmonic transform that constrains resolution and efficiency. We present Unified Spherical Frontend (USF), a distortion-free lens-agnostic framework that transforms images from any calibrated camera onto the unit sphere via ray-direction correspondences, and performs spherical resampling, convolution, and pooling canonically in the spatial domain. USF is modular: projection, location sampling, value interpolation, and resolution control are fully decoupled. Its configurable distance-only convolution kernels offer rotation-equivariance, mirroring translation-equivariance in planar CNNs while avoiding harmonic transforms entirely. We compare multiple standard planar backbones with their spherical counterparts across classification, detection, and segmentation tasks on synthetic (Spherical MNIST) and real-world (PANDORA, Stanford 2D-3D-S) datasets, and stress-test robustness to extreme lens distortions, varying FoV, and arbitrary rotations. USF scales efficiently to high-resolution spherical imagery and maintains less than 1\% performance drop under random test-time rotations without training-time rotational augmentation, and enables zero-shot generalization to any unseen (wide-FoV) lenses with minimal performance degradation.}}